


深度学习里超耗资源的卷积计算如何加速?
如果你问我:深度学习芯片里最重要的加速器是什么?
我一定会不假思索的告诉你:最重要的是卷积计算加速器。
卷积(Convolution)计算几乎是近些年深度学习成功的最关键要素。
在包含卷积计算的CNN(Convolution)诞生之前,深度学习是由DNN家族统治的。DNN的权重(Weight)参数比CNN大很多。由于DNN的参数太大,这使得DNN的训练比CNN要困难,进一步使得DNN的层数不能太多(训练层数太多,会导致消耗的算力呈指数增长,不好收敛)。同时计算起来也要慢。
DNN像是一个矮胖子,又重又矮又慢。眼神也不太好(精度比CNN低)。在DNN统治的时代,深度学习还没有现在这么多粉丝。
后来,英明神武的CNN家族带着满身的卷积核登场了。CNN把DNN中每一个通道(Channel)的全连接计算(大量参数)改成了统一的卷积核(少量参数,一般是3X3个)。通过这样瘦身,CNN身轻体健好训练,层数一下多了起来。
CNN家族就是深度学习界的美男子,又高又轻又快,表现也好。可以说,深度学习中大量超过人类平均水平的优异表现都与CNN中的卷积核有关。
一,卷积是什么样
先来说说,卷积是什么样。
常见的卷积核(一个通道与下一层的一个通道之间)一般是1X1或3X3的矩阵。下面以3X3的卷积核的卷积操作来说明。
卷积操作的对象的特征图(Feature Map)。实际的特征图一般会有多个通道,形成三维矩阵。为了方便大家理解,这里先按按一个通道简化考虑。例如:输入的特征图为5X5的矩阵形式(仅有一个通道)。矩阵中每个元素表示为F(i,j)。I对应行,j对应列。(角标从0开始)
卷积核是3X3大小的矩阵形式。矩阵中每个元素表示为C(i,j)。I对应行,j对应列。(角标从0开始)
那么下图中一次卷积操作的计算可以表示为:
G(0,1)= F(0,1)xC(0,0)+ F(0,2)xC(0,1)+ F(0,3)xC(0,2) ——第一行
+ F(1,1)xC(1,0)+ F(1,2)xC(1,1)+ F(1,3)xC(1,2) ——第二行
+ F(2,1)xC(2,0)+ F(2,2)xC(2,1)+ F(2,3)xC(2,2) ——第三行
卷积操作之后再做激活。
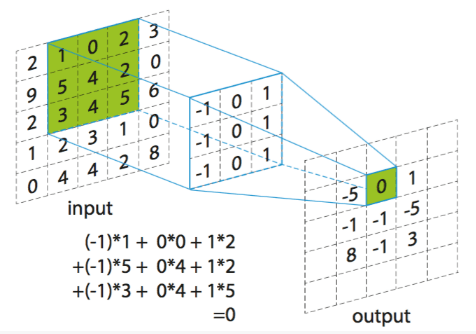
单次卷积操作
比较形象的卷积操作可以看下图:
卷积的形象表示(动画)
在实际计算中,还有Padding和Stride操作。(这些内容我们会在具体网络介绍中说明)
二,卷积计算加速的(硬件)方法
那么,如何做卷积计算的加速呢?
一般来说,可以用硬件电路的方法加速,也可以用算法的方式进行加速(例如算法压缩、卷积核分解等)。
这里我们先介绍硬件加速方式。算法压缩等技术我们会在后面的文章专门介绍。
卷积加速的基本思路是并行化。
下图是一个典型的AI芯片中的并行计算架构:
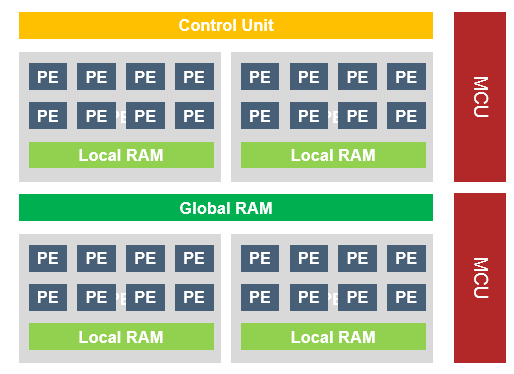
计算的并行化
图中的PE(Processing Element)是进行卷积运算的基本单元。一般来说,一个PE相当于一组乘加器(MAC)或DSP(FPGA中的叫法)。卷积中的每一个乘加计算,都会由一组PE来执行。在一个通道卷积计算中,就会有很多组PE同时进行计算。
当然,由于片上嵌入式存储器(一般是eSRAM。寒武纪为了提升内部存储容量,使用了TSMC的eDRAM)的限制,计算时需要不断的把weight和feature map在芯片内部的SRAM中进行乾坤大挪移。
有同学可能会问:为什么片内的存储器不够用?这里要解释下:大家看AI芯片Paper的,里面的实验一般会用LeNet这个祖宗级的模型来跑。但实际上现在商用的CNN多数是巨大的,例如YoloV3的Weight在200MB以上;同时要处理的Feature Map也多是512x512x128B以上的。Paper中的美好,并不能抵挡现实计算的残酷。
为了保证计算的高效和降低对内存带宽的限制,这些PE计算的顺序是有规则的。
我们这里只介绍AI芯片中用的最多的,也最有效的计算顺序。(不浪费大家的宝贵时间)
1)卷积核(缓存)优先
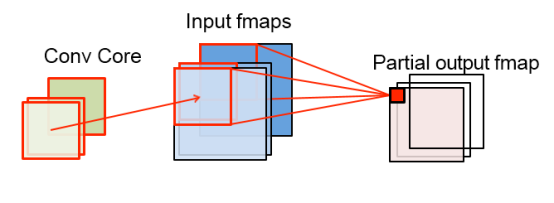
卷积核优先
在计算时,把(几乎全部)卷积核存在片内存储中,逐段计算Feature Map的方式,称为卷积核(缓存)优先。(作者自己造的名词哦)
如上图,在这一计算过程中,(几乎全部)Weight存在片上存储中,同时计算若干通道的卷积(累加是以流水线的方式同时进行的)。计算出来的部分Feature Map经过短暂的缓存就被转存到片外的DRAM中。
在这一计算规则下,Weight不必重复从DRAM中load进片内存储,大概可以节约k x k x W x H次DRAM读取。
2)特征图多区域并行
如果内部的MAC足够多,可以同时计算特征图的多个区域。这些区域共用卷积核,同时计算Fature Map上不同的区域。
计算不同区域的好处是,不同区域的DRAM存储地址不连续,不会涉及对同一内存地址的同时操作。因此可以通过流水线技术交叉操作。
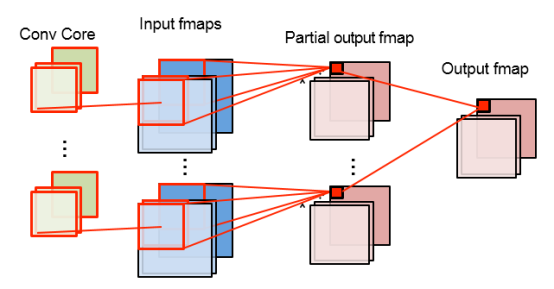
特征图多区域并行
3)卷积计算的流水线作业
这个大家看图就会明白。
局部卷积的计算与累加是按照流水线的方式加速的。同时,计算与DRAM操作也是按流水线组织的。这个技术是CPU中常见的技术故不再详述。
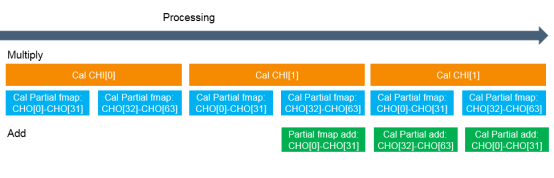
卷积计算的流水线作业
4)卷积核-特征图交织技术与类霍夫曼硬解码
卷积核计算的加速,除了上面介绍的内容,还有卷积核-特征图交织技术与类霍夫曼硬解码(不是传统的霍夫曼)。这两个技术的加速效果比上面的更明显,而且可以有效降低对片上存储的容量要求。但由于这两个是商业级的技术,做过的都明白,没做过的也不能告诉你们。。。就不进行细节说明了。
关于TensorChip
TensorChip(千芯科技)的研发核心团队由来自北美AI巨头、瑞萨与国内的芯片及人工智能领域资深专家组成,致力于国际领先的AI算法-芯片协同设计(算芯协同),聚焦AI算法及芯片系统在应用领域的落地。合作方包括兆易创新、深圳清华大学研究院、新松机器人、四维图新等国内顶尖的技术领跑者。
TensorChip目前正通过定制化合作,协助客户将自有算法在FPGA平台、RISC-V架构、及x86架构产品落地。合作伙伴包括AI芯片企业与AI算法企业。未来,TensorChip会与合作伙伴一起,推出可重构的存算一体芯片方案和对应的算法编译平台,在人工智能批量投产时代提供最具市场竞争力的芯片平台方案。
